2023/1/25:記事の調整のために色々なよく見るモデルをDLしに行ったところ、製作者様が差し替えてくれたのか、破損のあるものがかなり減っていました。
修正手段も楽になってきているので、今後はあまり気にしなくて良いかもしれません。
簡易ジェネレーター
詳しい説明は下の項目を読んで下さい。利便性のためにジェネレーターを一番上にしました。
毎度入力ダルいわ! て方のために、Googleスプレッドシート版も作りました。
こちらなら自分の所にコピーして使って頂ければパスとかそのまま保存しておけます。
前回のChatGPTジェネレーターの別シートになっていますので、下のシートタブからModel修復を選んでください。
まずPowerShellで以下を入力(コピペでOK)何も出なければまずPythonが入っていません。
python -V次にpipとsetuptoolsの更新をします。
python -m pip install --upgrade pip setuptools次にsafetensorsの更新をします。
pip install safetensors次にPyTorchの更新をします。
pip install torchこれで問題ないはずです。
Anacondaで環境を入れている場合はAnaconda環境から実行する必要あり。
実行しているモデルが.yamlファイルが必要なものの場合はこの方法でチェックと修復できなさそうな感じです。(私も詳しくはないので詳細はよくわかりません。有識者の方教えてください。)
下記の記事でも解説されています。こちらのやり方ならWebUIが動いている環境であれば問題なく実行できるかと思いますので、是非参考にして頂ければと思います。
破損とはなにか
トークンを処理する部分が壊れるようです。(ざっくり)
特定のトークン目が無視されたり、重複して強調がかかったりするような事態が発生します。
ここの説明では詳しいことは省き、どうすればいいのかという所だけ解説しますので、詳しくは下記の解説サイトを御覧ください。非常にわかりやすくまとまっています。
その1~3まであります。

破損チェック方法
先程の解説サイトの、その3からfix_position_ids.pyをDL
こちら↓
https://note.com/api/v2/attachments/download/e3c65d6a4c341171fe6fccad4f1a13b0
DLしたpyファイルの置く場所はどこでもいいです。
fix_position_ids.py使い方
pyファイルが置いてあるフォルダでShiftを押しながら右クリックします。
PowerShellウィンドウをここで開くをします。
出てきたウィンドウに次のように打ち込みます。
(拡張子のckptとsafetensorsを間違えないようにしてください)
※最初のジェネレーターで一発で出ます。
python fix_position_ids.py --model モデルのパス\モデル名.モデル拡張子 --verbose
実際の例↓
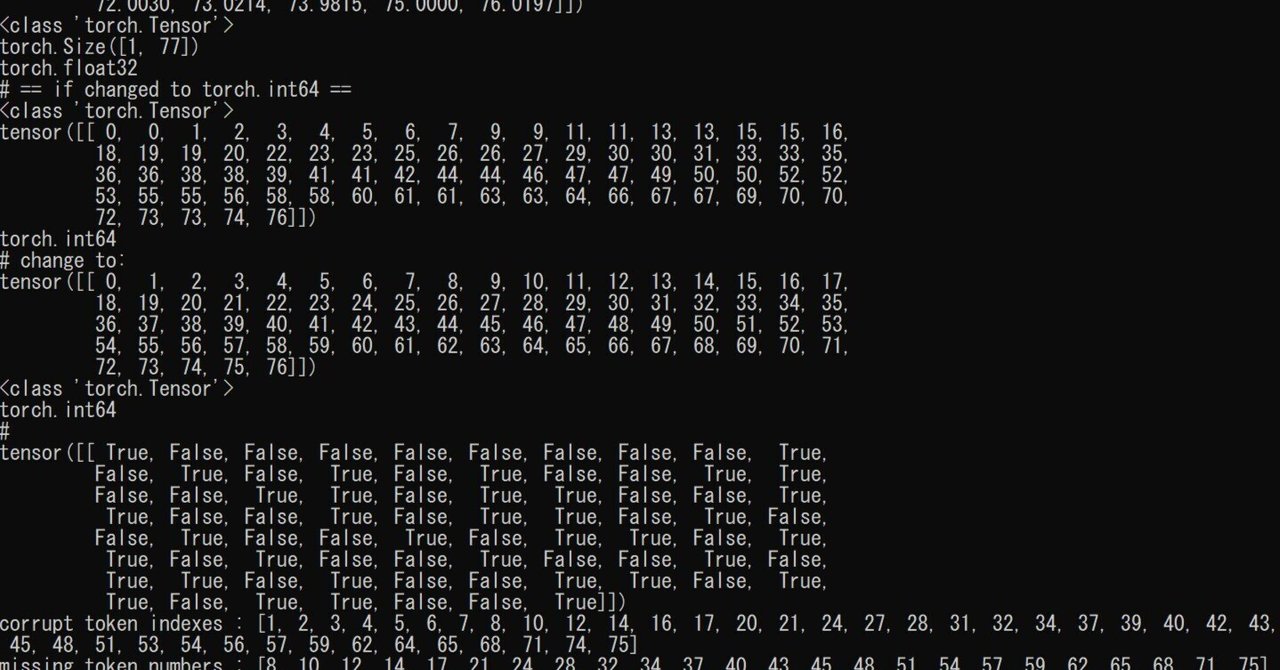
python fix_position_ids.py --model D:\_C\download\ckpt\anything-v4.5.safetensors --verboseスキャン結果
モデル名は伏せますが、破損があります。
まず数字の重複ですが、重複したナンバーのトークンは2回呼び出されるので強調されます。
次に数字のスキップですが、スキップされたナンバーのトークンは無かったことにされます。
(この解釈であっているはずですが、違っていたら教えてください)
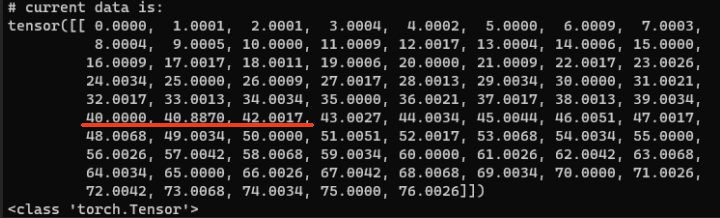
また、整数ではなく小数点になっている事も問題です。数字が綺麗に並んでいても小数点が生じていると問題がある事になります。(型指定の問題ですが詳しくは省きます)
数字が並んでいる所は全てが整数で数字が飛ばされていないこと、下段が全部Trueになっていることを確認してください。(小数点じゃなくても数字が飛んでいることがあります)
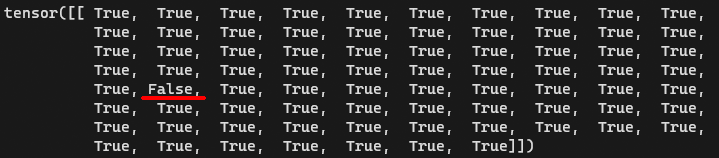
破損があるままモデルマージを行うとマージ先にも影響しますので、どんどん壊れていく事もありえます。
2023/1/24までACertainThingのスキャン画像を掲載していましたが、製作者ご本人様からあれは意図して結果重視でやっているものであり、破損ではありません。との事です。
また、Unetの調整をTextEncoderからの調整の必要も感じないという旨の追伸もありました。このあたりの技術は難しい所が多いので私からは何とも言えません。
訂正し、謹んでお詫び申し上げます。

直す方法
直し方はいくつかありますが、2つ紹介します。
まずこのままfix_position_ids.pyを使用する方法とExtensionのmodel-toolkitを使用する方法です。
model-toolkitはついでにモデルの圧縮までできるので、こっちの方が楽かもしれないですね。
ckpt→safetensorsの変換もできます。
fix_position_ids.pyを使用して直す
PowerShellに下記のように打ち込みます。
※最初のジェネレーターで一発で出ます。
python fix_position_ids.py --model モデルパス\モデル名.モデル拡張子 --out 変換後モデルの保存先パス\変換後モデルの名前.拡張子(ここは変換前と同じにしてください)
↓実際の例
python fix_position_ids.py --model D:\_C\download\ckpt\ACertainThing.ckpt --out H:\AI\models\need_fix\ACertainThing_fix.ckpt名前にFixとか入れておくと分かりやすいと思います。
model-toolkitを使用して直す(モデル圧縮・VAE同梱も可能)
model-toolkitをインストールします。
GitURL
インストール方法が分からない方は下記を参照ください。
事前設定
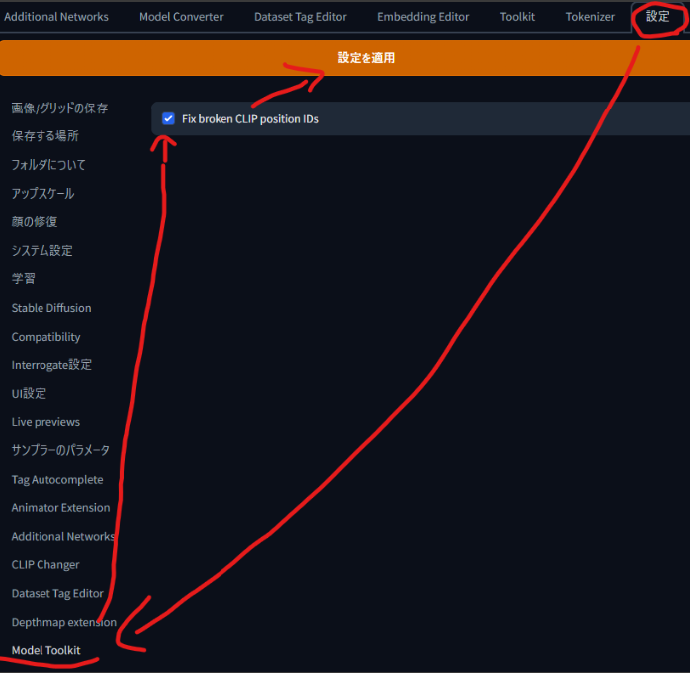
設定画面からModel Toolkitを選択し、Fix broken CLIP position IDsにチェックを入れて、設定の適用を押します。これでモデル破損が直せます。
使い方
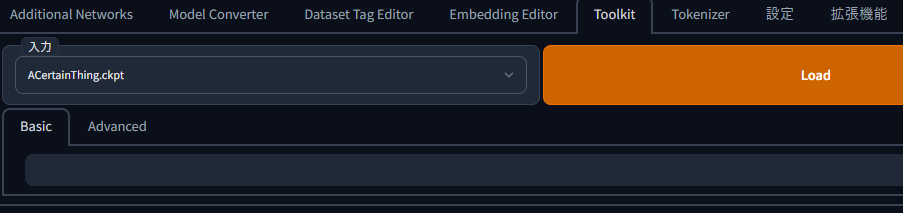
入力から変換したいモデルを選び、Loadを押します。
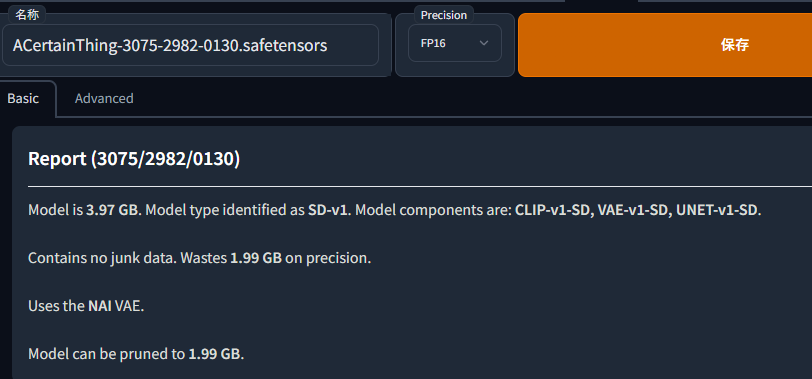
ロードが終わると下の画面が出てきます。
・モデル名(このままで良ければ特に変える必要なし)拡張子を変えれば形式も変えられます。
特別な理由がない限り.safetensorsでいいと思います。
・Precision:モデルの圧縮率に関係します。FP16(小さい)FP32(フルサイズ)
※圧縮する場合ema領域が消えるので再学習を予定している方は注意です。
FP16にしてもxformersのON,OFF程度の違いしか無いと言われていますが、多少なりとも変化はあるので気になる方は両方出して比較してみるといいと思います。
一応置いておきます。SEEDとVariation seed固定で出したものです。
←FP16,FP32→


保存ボタンを押せば終わりです。
また、Advanced設定の方ではVAEを同梱する機能があります。
私はVAEで彩度とか調整するので同梱させるメリットは特にないのでやっていませんが、このモデルならこのVAEを使うって決まっている人は同梱する方がメリットもあるかもしれません。ちなみに同梱するとVRAM節約できるので出力できる最大解像度が上がるらしいです。(未検証)
VAEを同梱する
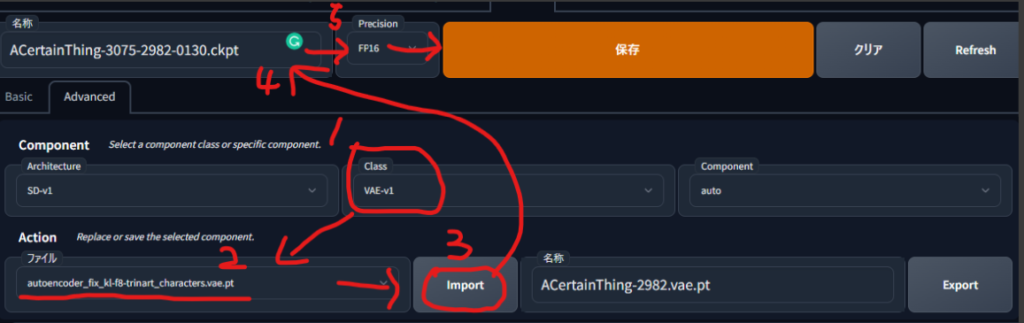
Advancedに移動し、ClassからVAE-v1を、Actionから適用するVAEを選び、Importを押します。
(ArchitectureはそのままComponentはautoでOKです)
保存ボタンの左の名称の所を分かりやすい名前(_addVAEなど?)にして保存をおします。
以上で、モデルの修正と圧縮の説明を終わります。

